[toc]
python基础十四 模块
重点
##os模块
#文件夹相关
os.makedirs('dirname1/dirname2') 可生成多层递归目录 ***
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 ***
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname ***
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname ***
#文件相关
os.remove() 删除一个文件 ***
os.rename("oldname","newname") 重命名文件/目录 ***
#路径相关
os.path.abspath(path) 返回path规范化的绝对路径 ***
os.path.split(path) 将path分割成目录和文件名二元组返回 ***
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False ***
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False ***
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False ***
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 ***
os.path.getsize(path) 返回path的大小 ***
#sys模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 ***
1. 模块介绍
py文件就是一个模块
2. 模块分类
2.1 内置模块
内置模块也叫标准库
2.2 第三方模块
别人写好的功能
2.3 自定义模块
自己写的特定功能
3. 模块作用
1.开发效率高,有大量的内置函数和模块
2.拿来主义,大量的第三方模块,拿来既能用,不需要知道原理
3.减少重复代码,分文件管理,有助于修改和维护
4. 模块使用
4.1 语法
import 模块名
4.2 模块的两种用法
1.当作普通模块执行
2.被当作脚本执行
5. 自定义模块
自定义模块使用示例
//非同级目录示例
1.在当前需要调用模块的py文件test.py的不同路径新建一个文件i.py,一会test.py调用这个文件i.py
2.在/Users/baixuebing/Desktop下创建一个i.py文件,文件内如下
print("非同级目录自定义模块路径导入练习")
a = 10
b = 20
3.test.py文件内容如下
import sys #需要导入sys模块
sys.path.append('/Users/baixuebing/Desktop') #这里写要导入的自定义模块的路径
from i import a,b #自定义模块名是i,导入a,b两个功能
print(a,b) #打印功能
非同级目录自定义模块路径导入练习
10 20
//同级目录示例
说明:test.py文件与自定义模块i.py在同一个路径下
from i import a,b
print(a,b)
同级目录自定义模块导入练习
10 20
5.1 自定义模块特殊说明
应用场景:
1.现在有一个自定义模块i.py,文件内容如下
def login():
print('登陆')
def register():
print('注册')
print('自定义模块保留自定义内容不被调用')
print(123456)
调用者文件test.py,文件内容如下
import sys
from i import login
login()
2.导入这个自定义模块并执行,返回结果如下,但是自定义模块中调用函数的123456不想被调用,需要做一下特殊处理,让调用者只能看到 ’自定义模块保留自定义内容不被调用‘、登陆、注册,不能看到123456
自定义模块保留自定义内容不被调用
123456
3.修改自定义模块i.py,在a()和b()的上方加入一行代码
if __name__ == "__main__":
def a():
print('登陆')
def register():
print('注册')
print('自定义模块保留自定义内容不被调用')
if __name__ == "__main__":
#不可外传功能
print(123456)
4.调用者再次执行,结果如下,结果123456无法获取
自定义模块保留自定义内容不被调用
登陆
🌟🌟🌟
原因:
在当前文件i.py中执行__name__获取的值是'__main__'
当前文件i.py被当作模块导入时,__name__获取的是当前文件名
6. 模块导入
6.1 模块导入过程
1.将模块存储到当前名称空间中,可以使用globals查看
2.以模块的名字命名,并开辟一个独立空间
3.通过模块名来使用模块中的功能
6.2. 导入说明
6.2.1 全部导入
import 模块名 是将模块中所有的内容全部倒入
6.2.2 导入部分
from 模块名 import 功能1,功能2 从模块中导入部分功能
from 模块名 import 功能1 as 别名
6.3 模块导入注意点⚠️
1.同一个模块,写多次,只执行一次
6.4 模块导入顺序
内存 --> 内置 --> sys.path
7. 模块路径
模块与py文件在同一路径可以直接调用
模块与py文件不在同一路径,需要导入sys模块及导入模块路径
import sys
sys.path.append('路径')
8. 模块查找顺序
内存 --> 内置 --> sys.path
9. time模块
9.1 时间分类
9.1.1 时间戳 用于计算
通常的叫法,时间戳表示的是格林尼治时间是从1970年1月1日00:00:00开始按秒计算的偏移量。这个是实时变化的。我们运行“type(time.time())”,返回的是float类型
#获取时间戳
import time
print(time.time())
1569543159.206561
9.1.2 结构化时间 用于程序员获取数据结构 命名元组
#获取结构化时间
import time
t = time.time() #获取时间戳
print(time.localtime(t)) #将时间戳转换为结构化时间
time.struct_time(tm_year=2019, tm_mon=9, tm_mday=27, tm_hour=8, tm_min=22, tm_sec=41, tm_wday=4, tm_yday=270, tm_isdst=0)
9.1.3 字符串时间 给用户查看的
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
#获取字符串时间
import time
print(time.strftime("%Y-%m-%d %X"))
2017-09-27 08:18:32
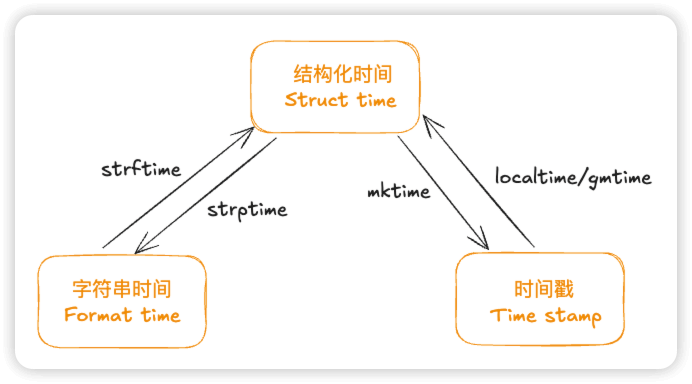
9.2 三种时间相互转换
9.2.1 字符串时间 <-->结构化时间
import time
str_time = "2019-9-1 12:23:06"
print(time.strptime(str_time,"%Y-%m-%d %H:%M:%S")) # 将字符串时间转换成结构化时间
time.struct_time(tm_year=2019, tm_mon=9, tm_mday=1, tm_hour=12, tm_min=23, tm_sec=6, tm_wday=6, tm_yday=244, tm_isdst=-1)
t = time.localtime() #先获取结构化时间
print(time.strftime("%Y-%m-%d %H:%M:%S",t)) #将结构化时间转换成字符串时间
9.2.2 时间戳 <--> 结构化时间
import time
t = time.time() #获取时间戳
print(t)
1569543714.778055
print(time.localtime(t)) #将时间戳转成结构化时间
time.struct_time(tm_year=2019, tm_mon=9, tm_mday=27, tm_hour=8, tm_min=22, tm_sec=41, tm_wday=4, tm_yday=270, tm_isdst=0)
t = time.localtime() #先获取结构化时间
print(time.mktime(t)) #将机构化时间转换成时间戳
1569564152.0
9.2.3 字符串时间 <--> 时间戳 需要先转换为中间人结构化时间再转换,不能直接转化
字符串时间<---->结构化时间<---->时间戳
10. datetime模块
# import datetime ⚠️此写法不正确
1.获取当前时间,是一个对象,不是字符串
from datetime import datetime
print(datetime.now())
2017-10-03 18:58:09.455678
print(type(datetime.now()))
<class 'datetime.datetime'>
2.自定义时间
print(datetime(2016,11,11,11,11,11))
2016-11-11 11:11:11
3.时间戳转换成对象
import time
print(datetime.fromtimestamp(time.time()))
2017-10-07 18:27:43.683452
4.将对象转换成时间戳
print(datetime.timestamp(datetime.now()))
1570444141.19223
5.将对象转换成字符串
print(datetime.strftime(datetime.now(),"%Y-%m-%d %H:%M:%S"))
2017-10-07 18:29:50
6.将字符串转换成对象
print(datetime.strptime("2016/11/11","%Y/%m/%d"))
2016-11-11 00:00:00
7.对象时间与自定义时间做运算
print(datetime.now() - datetime(9999,11,1,12,13,14))
-2914660 days, 6:20:23.854611
8.计算从当前对象时间到某一天
from datetime import datetime,timedelta
print(datetime.now())
print(datetime.now() - timedelta(days=1))
print(datetime.now() + timedelta(days=1))
2017-10-07 18:37:18.013572
2017-10-06 18:37:18.013611
2017-10-08 18:37:18.013628
11. random模块 随机数
1.获取0-1之间的小数
import random
random.random() #0-1之间的小数
2.获取范围的随机整数
random.randint(1,5) #获取1-5之间的整数
3.获取范围内的随机偶数
random.randrange(0,10,2)
4.获取列表中单个元素
lst = [1,2,3,4,5,6]
random.choice(lst)
5.获取列表中指定个数元素
lst = [1,2,3,4,5,6]
random.choices(lst,k=5) #随机获取5个数,会出现重复元素
random.sample(lst,k=5) #随机获取5个数,不会出现重复元素
6.打乱顺序
lst = [1,2,3,4,5,6,7,8]
random.shuffle(lst)
12. sys模块 与python解释器做交互
1.获取系统路径
import sys
sys.path
2.获取系统平台
sys.platform
windowns --> win32
mac --> darwin
3.获取当前py文件路径
sys.argv #返回列表
4.获取python解释器版本
sys.version
5.退出码
sys.exit(1) #0是正常退出,可以修改
6.获取所有模块
sys.modules()
13. os模块
13.1 文件
1.修改文件名
import os
os.rename("旧名","新名")
2.删除文件
os.remove("要删除的文件名")
13.2 文件夹
1.创建文件夹
os.makedirs('a/b/c') #递归创建
os.mkdir('a') #单�独创建
2.删除文件夹
os.removedirs('a') #递归删除
os.rmdir('a') #删除文件夹
3.查看文件夹
os.listdir() #查看当前路径下所有的文件
13.3 路径
1.获取路径
os.getcwd() #获取当前工作路径
2.切换路径
os.chdir() #切换路径
3.获取当前路径
os.curdir()
4.获取上级目录
os.pardir()
5.获取绝对路径 ⚠️重要 注意是当前路�径下的文件或者文件夹
os.path.abspath('当前文件或者文件夹名')
6.路径分割 ⚠️只分一刀 获得的是元组
os.path.split('路径')
7.父级目录 ⚠️⚠️⚠️ 🌟
os.path.dirname('路径')
8.获取路径最外层
os.path.basename('路径')
9.将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 🌟🌟🌟
os.path.join('路径1','路径2'.'路径3')
10.获取文件大小
os.path.getsize()
is系列
1.判断路径是否存在 返回布尔值
os.path.exists()
2.判断是否是绝对路径 返回布尔值
os.path.isabs()
3.判断是否是存在的文件
os.path.isfile('绝对路径')
4.判断是否是目录
os.path.isdir()
13.4 其他
1.执行shell命令
os.system()
os.popen('dir').read()
2.获取环境变量
os.environ()
14.hashlib模块
14.1 含义
摘要算法,加密算法
14.2 功能
加密,校验一致性
14.3 加密说明
1.内容相同,密码一定相同
2.加密的密文是不可逆的
3.明文-->字节-->密文
4.加密方法 md5、sha1、sha256、sha512
14.4 加密示例
import hashlib #导入hashlib模块
s = "123abc"
md5 = hashlib.md5() #选择加密的方式,初始化一个加密
md5.update(s.encode("utf-8")) #将要加密的内容添加到变量md5中
print(md5.hexdigest()) #进行加密
14.5 加盐
14.5.1 固定加盐
user = input("user:")
pwd = input("pwd:")
import hashlib
md5 = hashlib.md5("abc".encode("utf-8")) #这里的abc就是盐
md5.update(pwd.encode("utf-8"))
print(md5.hexdigest())
14.5.1 动态加盐
user = input("user:")
pwd = input("pwd:")
import hashlib
md5 = hashlib.md5(user.encode("utf-8")) #这里的user就是动态盐
md5.update(pwd.encode("utf-8"))
print(md5.hexdigest())
15.collections模块
15.1 统计 🌟🌟🌟
//示例 统计列表中每个元素出现的次数
#方法1 for循环
lst = [1,1,2,5,6,7,7,9,99,99,1,3,7]
dic = {}
for i in lst:
dic[i] = lst.count(i)
print(dic)
{1: 3, 2: 1, 5: 1, 6: 1, 7: 3, 9: 1, 99: 2, 3: 1}
#方法2 collections记数
lst = [1,1,2,5,6,7,7,9,99,99,1,3,7]
from collections import Counter
print(dict(Counter(lst)))
{1: 3, 2: 1, 5: 1, 6: 1, 7: 3, 9: 1, 99: 2, 3: 1}
15.2 有序字典 🌟🌟🌟 python2中使用
from collections import OrderedDict
a = OrderedDict({"key1":1,"key2":2})
print(a)
print(a["key1"])
OrderedDict([('key1', 1), ('key2', 2)])
1
15.3 默认字典
from collections import defaultdict
dic = defaultdict(list) #括号中写不加括号的方法 例如列表只写list,不写list(),这里字典默认值就是空列表
dic['k1'].append(10) #指明字典的值为10
dic['k2'] #不指定字典的值,默认是空列表
print(dic)
defaultdict(<class 'list'>, {'k1': [10], 'k2': []})
//示例题 将列表中元素大于66的追加到字典的key1中,小于66的追加到字典的key2中
#方法1
lst = [11,22,33,44,55,77,88,99]
dic = {"key1":[],"key2":[]}
for i in lst:
if i > 66:
dic['key2'].append(i)
else:
dic['key1'].append(i)
print(dic)
{'key1': [11, 22, 33, 44, 55], 'key2': [77, 88, 99]}
#方法2
lst = [11,22,33,44,55,77,88,99]
dic = {}
for i in lst:
if i > 66:
dic.setdefault('key2',[]).append(i)
else:
dic.setdefault('key1', []).append(i)
print(dic)
{'key1': [11, 22, 33, 44, 55], 'key2': [77, 88, 99]}
#方法3
from collections import defaultdict
lst = [11,22,33,44,55,77,88,99]
dic = defaultdict(list)
for i in lst:
if i > 66:
dic['key2'].append(i)
else:
dic['key1'].append(i)
print(dic)
defaultdict(<class 'list'>, {'key1': [11, 22, 33, 44, 55], 'key2': [77, 88, 99]})
15.4 双端队列
1.队列 先进先出 deque 🌟🌟🌟
from collections import deque
lst = deque([11,22,33,44,55])
lst.appendleft(00) #从左侧开始追加
print(lst)
deque([0, 11, 22, 33, 44, 55])
lst.popleft() #从左侧开始删除
print(lst)
deque([22, 33, 44, 55])
2.栈 先进后出
lst = []
lst.append(1)
lst.append(2)
lst.append(3)
print(lst)
lst.pop()
print(lst)
lst.pop()
print(lst)
lst.pop()
15.5 命名元组 namedtuple 🌟🌟🌟
from collections import namedtuple
dg = namedtuple('name',["aa","bb","cc"])
print(dg('hehe','haha','xixi'))
name(aa='hehe', bb='haha', cc='xixi')